Agencies that treat AI search as one unified field will develop strategies that partially succeed, but not entirely. Each AI search platform has specific technical needs alongside common requirements that apply to all of them equally.
The Foundational Layer: What All AI Search Systems Need
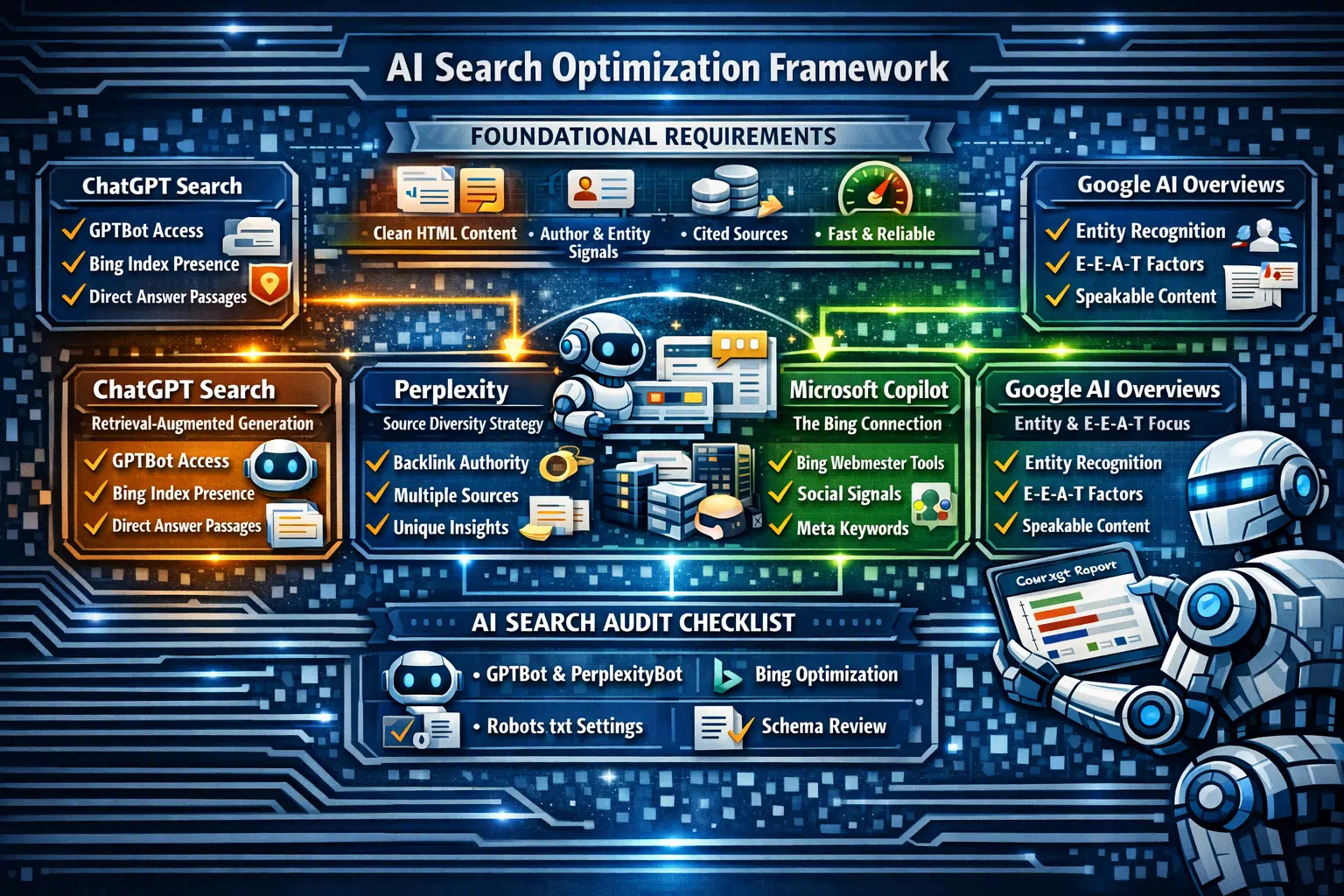
Before delving into the particulars for each platform, there is a baseline set of technical requirements that any AI search system — whether Google, OpenAI, Perplexity, or Anthropic — needs in order to consider citing a page.
Parseable content structure. An AI search engine parses HTML pages to find passages worth quoting. Content hidden behind JavaScript, contained within iframes, or displayed as an image cannot be parsed by most AI bots. The main content on any page, especially parts that are citation-worthy, needs to be present in HTML and tagged with heading sections from H1 through H3.
Clarity of author and organisation. Every AI system uses some kind of credibility assessment of sources. For written sources, it is important for the author to be known and verifiable, with credentials confirmable from independent sources. For organisations, the same principle applies — their identity should be verifiable based on a Google Business Profile, LinkedIn page, and other structured sources.
Factuality and source citation. AI systems retrieving information to include in an answer tend to prefer pages making verifiable claims based on named or cited sources and data. These pages are favoured over pages making vague or unverifiable statements or pages that contain no credible source citations or attribution at all.
Page speed and availability. AI search engines cache and recrawl pages on varying schedules. Pages that were slow or unavailable at the time of a crawl may be dropped from consideration until the next crawl cycle. The relationship between Core Web Vitals performance and citations holds true even beyond Google Search use cases.
Agencies that treat AI search optimisation as a single discipline will find results that are incomplete. The technical requirements diverge meaningfully across platforms — and understanding those differences is what separates a checklist from a real strategy.
ChatGPT Search: Retrieval-Augmented Generation and What It Means Technically
The ChatGPT search engine utilises retrieval-augmented generation (RAG). After receiving a query, the search engine selects candidate pages from OpenAI's index, retrieves information from those pages, and feeds the relevant content as input to the language model to produce an output answer. The citation in the answer refers to the source from which information was extracted.
Crawlable by GPTBot. OpenAI's crawler is named GPTBot and can be allowed or disallowed through robots.txt. GPTBot is frequently blocked by catch-all disallow statements. Verifying that GPTBot is permitted is the first technical check required before targeting ChatGPT citations.
Indexed in OpenAI's index. OpenAI maintains its own web index, separate from Google's. A substantial portion of this index draws from Bing — because of Microsoft's investment in OpenAI, content indexed in Bing Webmaster Tools has an architectural edge when it comes to ChatGPT citation eligibility.
Answer passages that can be directly extracted. ChatGPT retrieval favours pages that provide a concise, self-contained answer to a common question — preferably within the first 20% of the page, under a distinct heading, and without requiring context from elsewhere on the page to interpret it. This parallels the structure required for Google's Featured Snippets.
Perplexity: Diverse Sources and Domain Authority Indicators
What sets Perplexity apart is that it tries to cite several different sources for the same answer. Pages do not necessarily have to be considered the most authoritative on a topic to be included as citations — all that is required is that the page provides a unique contribution to the existing set of sources.
For agency clients, this presents a useful strategy: identifying the individual sub-claims or specific pieces of information that the client's page is uniquely positioned to provide within a broader topic area.
Perplexity employs PerplexityBot as its crawler, and permission should be granted in robots.txt. Perplexity appears to rely on domain authority indicators based on external links more heavily than some other AI platforms — which means that traditional link-building remains an important factor in Perplexity citation coverage, as opposed to the entity-based indicators that matter more for Google AI Overviews.
Microsoft Copilot: The Bing SEO Link
Microsoft Copilot's content retrieval draws from Bing's index, which means Bing SEO is now more consequential than ever before in the context of Copilot citations. Agencies that have historically treated Bing optimisation as secondary can no longer afford to maintain that mindset.
The practical requirements include submitting sitemaps to Bing Webmaster Tools, resolving Bingbot crawl errors, and ensuring site verification within Bing. Bing is also known to weight certain technical factors differently from Google — including meta keywords, on-page keyword density, and LinkedIn social signals.
For B2B agencies serving clients in professional services verticals, a citation in Microsoft Copilot is especially relevant because it is deeply integrated with Microsoft 365. Copilot citations surface directly within the work environments of decision-makers using Outlook, Teams, and Word — a fundamentally different reach from a traditional search engine results page appearance.
Building an AI Search Audit Into Standard Technical SEO Delivery
The practical impact on agency teams is that AI search optimisation readiness needs to become a mandatory part of each technical SEO audit. The new checklist additions are limited but high-value:
AI Search Audit Checklist
GPTBot and PerplexityBot permissions in robots.txt
llms.txt file at the site root
Adding these checks to an existing technical SEO audit checklist takes only a few hours. Yet the advantage for the client is substantial — as AI search engines absorb an ever-larger share of informational query volume, clients who are technically ready will preserve and grow their organic presence while others gradually lose it.
Additional Resources
Pam Harper
Founder of Harper Media Group. 20+ years of web development, 12+ years of technical SEO. Specializing in technical SEO, structured data, and AI optimization — delivered white-label for agencies.
About Pam Harper